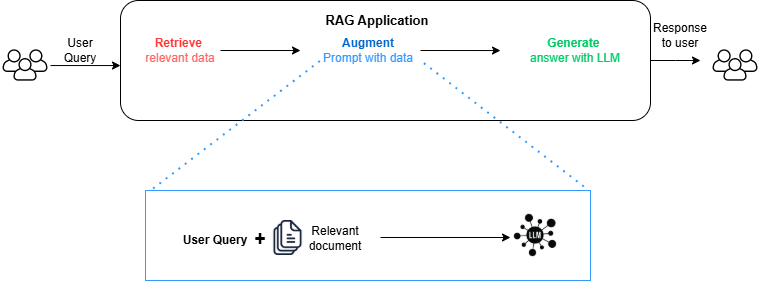
What is RAG
Retrieval Augmented Generation (RAG) is a way to improve responses from large language models (LLMs) like GPT-4 or Llama 2. It works by taking a user’s question and combining it with helpful external information to create a more detailed question for the model. This helps the model give answers that are more accurate, relevant, and up-to-date.
While LLMs are great at understanding and generating text, they aren’t always reliable sources of information. They don’t have access to private or recent information they weren’t trained on. Sometimes, they also "make things up" (called hallucinations) instead of admitting they don’t know the answer. RAG helps overcome these issues by providing the model with extra, trustworthy information to improve its responses.

RAG can use many types of data, like text, podcasts, videos, live search results, and structured databases. In this guide, we’ll focus on how RAG works with stored unstructured data, such as PDFs. Specifically, we’ll look at a RAG method where data is retrieved from vector databases using a process called Vector Search. This approach helps find and use the most relevant information for better responses.